
3 Commits
a1aa5ccff8
...
5a975b4e67
3 Commits
a1aa5ccff8
...
5a975b4e67
| Author | SHA1 | Message | Date |
|---|---|---|---|
 An Pham An Pham
|
5a975b4e67 | upload code | 1 month ago |
|
An Pham
|
cf188a47f4 | Merge branch 'master' into an | 2 months ago |
|
An Pham
|
96a76e04f1 | add project code | 2 months ago |
11 changed files with 7409 additions and 0 deletions
Unified View
Diff Options
-
+112 -0Project-scriptv1.2.R
-
+111 -0Project/Project2.R
-
+104 -0Project/Project_code.R
-
+38 -0Project/tempt-code.R
-
+7044 -0Telco-Customer-Churn.csv
-
BINbar_churn.png
-
BINbar_contract_churn.png
-
BINbar_internetservice_churn.png
-
BINboxplot_monthlycharges_churn.png
-
BINhist_monthlycharges.png
-
BINhist_tenure.png
+ 112
- 0
Project-scriptv1.2.R
View File
| @ -0,0 +1,112 @@ | |||||
| # Telco Customer Churn Analysis Script | |||||
| # Load required libraries | |||||
| library(ggplot2) | |||||
| library(dplyr) | |||||
| library(rpart) | |||||
| library(e1071) | |||||
| library(caret) | |||||
| library(pROC) | |||||
| # Load dataset | |||||
| telco <- read.csv("Telco-Customer-Churn.csv", stringsAsFactors = TRUE) | |||||
| telco\$TotalCharges <- as.numeric(as.character(telco\$TotalCharges)) | |||||
| telco <- telco\[!is.na(telco\$TotalCharges), ] | |||||
| telco\$Churn <- factor(telco\$Churn, levels = c("No", "Yes")) | |||||
| # Exploratory Data Visualizations | |||||
| # Histogram for numeric variables | |||||
| numeric\_vars <- c("tenure", "MonthlyCharges", "TotalCharges") | |||||
| for (var in numeric\_vars) { | |||||
| p <- ggplot(telco, aes\_string(x = var)) + | |||||
| geom\_histogram(binwidth = 10, fill = "skyblue", color = "black") + | |||||
| labs(title = paste("Histogram of", var), x = var, y = "Frequency") + | |||||
| theme\_minimal() | |||||
| ggsave(paste0("hist\_", var, ".png"), plot = p) | |||||
| } | |||||
| # Bar plot for churn | |||||
| p\_churn <- ggplot(telco, aes(x = Churn, fill = Churn)) + | |||||
| geom\_bar() + | |||||
| labs(title = "Churn Distribution", x = "Churn", y = "Count") + | |||||
| theme\_minimal() | |||||
| ggsave("bar\_churn.png", plot = p\_churn) | |||||
| # Boxplot of MonthlyCharges by Churn | |||||
| p\_box <- ggplot(telco, aes(x = Churn, y = MonthlyCharges, fill = Churn)) + | |||||
| geom\_boxplot() + | |||||
| labs(title = "Monthly Charges by Churn", x = "Churn", y = "Monthly Charges") + | |||||
| theme\_minimal() | |||||
| ggsave("boxplot\_monthlycharges\_churn.png", plot = p\_box) | |||||
| # Split data into training, validation1, and validation2 | |||||
| set.seed(100) | |||||
| n <- nrow(telco) | |||||
| train.index <- sample(1\:n, size = round(0.70 \* n)) | |||||
| remaining.index <- setdiff(1\:n, train.index) | |||||
| valid1.index <- sample(remaining.index, size = round(0.15 \* n)) | |||||
| valid2.index <- setdiff(remaining.index, valid1.index) | |||||
| train.df <- telco\[train.index, ] | |||||
| valid1.df <- telco\[valid1.index, ] | |||||
| valid2.df <- telco\[valid2.index, ] | |||||
| # Logistic regression model (simplified) | |||||
| logit.reg <- glm(Churn \~ SeniorCitizen + Dependents + tenure + MultipleLines + InternetService + Contract + | |||||
| PaperlessBilling + PaymentMethod + MonthlyCharges + TotalCharges, | |||||
| data = train.df, family = "binomial") | |||||
| summary(logit.reg) | |||||
| # Evaluate on validation set | |||||
| valid1\_pred\_probs <- predict(logit.reg, newdata = valid1.df, type = "response") | |||||
| valid1\_pred <- factor(ifelse(valid1\_pred\_probs > 0.5, "Yes", "No"), levels = c("No", "Yes")) | |||||
| logit\_conf <- confusionMatrix(valid1\_pred, valid1.df\$Churn, positive = "Yes") | |||||
| logit\_roc <- roc(response = valid1.df\$Churn, predictor = valid1\_pred\_probs) | |||||
| # Decision Tree model | |||||
| dt\_model <- rpart(Churn \~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, data = train.df, method = "class") | |||||
| dt\_pred <- predict(dt\_model, valid1.df, type = "class") | |||||
| dt\_conf <- confusionMatrix(dt\_pred, valid1.df\$Churn) | |||||
| # Naive Bayes model | |||||
| nb\_model <- naiveBayes(Churn \~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, data = train.df) | |||||
| nb\_pred <- predict(nb\_model, valid1.df) | |||||
| nb\_probs <- predict(nb\_model, valid1.df, type = "raw") | |||||
| nb\_conf <- confusionMatrix(nb\_pred, valid1.df\$Churn) | |||||
| nb\_roc <- roc(response = valid1.df\$Churn, predictor = nb\_probs\[,"Yes"]) | |||||
| # Print evaluations | |||||
| cat("\nLogistic Regression Confusion Matrix:\n") | |||||
| print(logit\_conf) | |||||
| cat("\nAUC (Logistic):", auc(logit\_roc), "\n") | |||||
| cat("\nDecision Tree Confusion Matrix:\n") | |||||
| print(dt\_conf) | |||||
| cat("\nNaive Bayes Confusion Matrix:\n") | |||||
| print(nb\_conf) | |||||
| cat("\nAUC (Naive Bayes):", auc(nb\_roc), "\n") | |||||
| # Save ROC curve plots | |||||
| png("logistic\_roc\_curve.png") | |||||
| plot(logit\_roc, main = "ROC Curve - Logistic Regression", col = "darkgreen") | |||||
| dev.off() | |||||
| png("naive\_bayes\_roc\_curve.png") | |||||
| plot(nb\_roc, main = "ROC Curve - Naive Bayes", col = "blue") | |||||
| dev.off() | |||||
+ 111
- 0
Project/Project2.R
View File
| @ -0,0 +1,111 @@ | |||||
| # Telco Customer Churn Analysis Script | |||||
| # Load required libraries | |||||
| library(ggplot2) | |||||
| library(dplyr) | |||||
| library(rpart) | |||||
| library(e1071) | |||||
| library(caret) | |||||
| library(pROC) | |||||
| # Load dataset | |||||
| telco <- read.csv("Telco-Customer-Churn.csv", stringsAsFactors = TRUE) | |||||
| telco\$TotalCharges <- as.numeric(as.character(telco\$TotalCharges)) | |||||
| telco <- telco\[!is.na(telco\$TotalCharges), ] | |||||
| telco\$Churn <- factor(telco\$Churn, levels = c("No", "Yes")) | |||||
| # Exploratory Data Visualizations | |||||
| # Histogram for numeric variables | |||||
| numeric\_vars <- c("tenure", "MonthlyCharges", "TotalCharges") | |||||
| for (var in numeric\_vars) { | |||||
| p <- ggplot(telco, aes\_string(x = var)) + | |||||
| geom\_histogram(binwidth = 10, fill = "skyblue", color = "black") + | |||||
| labs(title = paste("Histogram of", var), x = var, y = "Frequency") + | |||||
| theme\_minimal() | |||||
| ggsave(paste0("hist\_", var, ".png"), plot = p) | |||||
| } | |||||
| # Bar plot for churn | |||||
| p\_churn <- ggplot(telco, aes(x = Churn, fill = Churn)) + | |||||
| geom\_bar() + | |||||
| labs(title = "Churn Distribution", x = "Churn", y = "Count") + | |||||
| theme\_minimal() | |||||
| ggsave("bar\_churn.png", plot = p\_churn) | |||||
| # Boxplot of MonthlyCharges by Churn | |||||
| p\_box <- ggplot(telco, aes(x = Churn, y = MonthlyCharges, fill = Churn)) + | |||||
| geom\_boxplot() + | |||||
| labs(title = "Monthly Charges by Churn", x = "Churn", y = "Monthly Charges") + | |||||
| theme\_minimal() | |||||
| ggsave("boxplot\_monthlycharges\_churn.png", plot = p\_box) | |||||
| # Split data into training, validation1, and validation2 | |||||
| set.seed(100) | |||||
| n <- nrow(telco) | |||||
| train.index <- sample(1\:n, size = round(0.70 \* n)) | |||||
| remaining.index <- setdiff(1\:n, train.index) | |||||
| valid1.index <- sample(remaining.index, size = round(0.15 \* n)) | |||||
| valid2.index <- setdiff(remaining.index, valid1.index) | |||||
| train.df <- telco\[train.index, ] | |||||
| valid1.df <- telco\[valid1.index, ] | |||||
| valid2.df <- telco\[valid2.index, ] | |||||
| # Logistic regression model (simplified) | |||||
| logit.reg <- glm(Churn \~ SeniorCitizen + Dependents + tenure + MultipleLines + InternetService + Contract + | |||||
| PaperlessBilling + PaymentMethod + MonthlyCharges + TotalCharges, | |||||
| data = train.df, family = "binomial") | |||||
| summary(logit.reg) | |||||
| # Evaluate on validation set | |||||
| valid1\_pred\_probs <- predict(logit.reg, newdata = valid1.df, type = "response") | |||||
| valid1\_pred <- factor(ifelse(valid1\_pred\_probs > 0.5, "Yes", "No"), levels = c("No", "Yes")) | |||||
| logit\_conf <- confusionMatrix(valid1\_pred, valid1.df\$Churn, positive = "Yes") | |||||
| logit\_roc <- roc(response = valid1.df\$Churn, predictor = valid1\_pred\_probs) | |||||
| # Decision Tree model | |||||
| dt\_model <- rpart(Churn \~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, data = train.df, method = "class") | |||||
| dt\_pred <- predict(dt\_model, valid1.df, type = "class") | |||||
| dt\_conf <- confusionMatrix(dt\_pred, valid1.df\$Churn) | |||||
| # Naive Bayes model | |||||
| nb\_model <- naiveBayes(Churn \~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, data = train.df) | |||||
| nb\_pred <- predict(nb\_model, valid1.df) | |||||
| nb\_probs <- predict(nb\_model, valid1.df, type = "raw") | |||||
| nb\_conf <- confusionMatrix(nb\_pred, valid1.df\$Churn) | |||||
| nb\_roc <- roc(response = valid1.df\$Churn, predictor = nb\_probs\[,"Yes"]) | |||||
| # Print evaluations | |||||
| cat("\nLogistic Regression Confusion Matrix:\n") | |||||
| print(logit\_conf) | |||||
| cat("\nAUC (Logistic):", auc(logit\_roc), "\n") | |||||
| cat("\nDecision Tree Confusion Matrix:\n") | |||||
| print(dt\_conf) | |||||
| cat("\nNaive Bayes Confusion Matrix:\n") | |||||
| print(nb\_conf) | |||||
| cat("\nAUC (Naive Bayes):", auc(nb\_roc), "\n") | |||||
| # Save ROC curve plots | |||||
| png("logistic\_roc\_curve.png") | |||||
| plot(logit\_roc, main = "ROC Curve - Logistic Regression", col = "darkgreen") | |||||
| dev.off() | |||||
| png("naive\_bayes\_roc\_curve.png") | |||||
| plot(nb\_roc, main = "ROC Curve - Naive Bayes", col = "blue") | |||||
| dev.off() | |||||
+ 104
- 0
Project/Project_code.R
View File
| @ -0,0 +1,104 @@ | |||||
| # Load necessary libraries | |||||
| library(forecast) | |||||
| library(ggplot2) | |||||
| library(gplots) | |||||
| library(reshape) | |||||
| library(GGally) | |||||
| library(MASS) | |||||
| library(naniar) | |||||
| library(psych) | |||||
| # Load dataset | |||||
| setwd('/home/anpham/Nextcloud/cpp/Data Mining/Project') | |||||
| telco.df <- read.csv("Telco-Customer-Churn.csv", stringsAsFactors = FALSE) | |||||
| # Display first few rows | |||||
| head(telco.df) | |||||
| # Check structure | |||||
| str(telco.df) | |||||
| # Summary statistics | |||||
| describe(telco.df) | |||||
| # Convert categorical variables to factors | |||||
| categorical_vars <- c("gender", "SeniorCitizen", "Partner", "Dependents", "PhoneService", | |||||
| "MultipleLines", "InternetService", "OnlineSecurity", "OnlineBackup", | |||||
| "DeviceProtection", "TechSupport", "StreamingTV", "StreamingMovies", | |||||
| "Contract", "PaperlessBilling", "PaymentMethod", "Churn") | |||||
| telco.df[categorical_vars] <- lapply(telco.df[categorical_vars], factor) | |||||
| # Convert TotalCharges to numeric and handle missing values | |||||
| telco.df$TotalCharges <- as.numeric(telco.df$TotalCharges) | |||||
| telco.df$TotalCharges[is.na(telco.df$TotalCharges)] <- 0 | |||||
| # Create new feature: Average Monthly Spend | |||||
| telco.df$AvgMonthlySpend <- with(telco.df, ifelse(tenure > 0, TotalCharges / tenure, MonthlyCharges)) | |||||
| # Categorize tenure into groups | |||||
| telco.df$TenureCategory <- cut(telco.df$tenure, | |||||
| breaks = c(-Inf, 12, 48, Inf), | |||||
| labels = c("Short-Term", "Mid-Term", "Long-Term")) | |||||
| # Check missing values | |||||
| sum(is.na(telco.df)) | |||||
| colSums(is.na(telco.df)) | |||||
| # Visualize missing values | |||||
| gg_miss_var(telco.df) | |||||
| # Boxplots to detect outliers | |||||
| ggplot(telco.df, aes(y = MonthlyCharges)) + | |||||
| geom_boxplot(fill = "skyblue") + | |||||
| ggtitle("Boxplot of Monthly Charges") + | |||||
| theme_minimal() | |||||
| ggplot(telco.df, aes(y = TotalCharges)) + | |||||
| geom_boxplot(fill = "lightcoral") + | |||||
| ggtitle("Boxplot of Total Charges") + | |||||
| theme_minimal() | |||||
| # Histogram for numeric variables | |||||
| hist(telco.df$TotalCharges, col = "blue", main = "Distribution of TotalCharges") | |||||
| hist(telco.df$MonthlyCharges, col = "lightblue", border = "black", main="Distribution of Monthly Charges") | |||||
| # Density plot | |||||
| plot(density(telco.df$MonthlyCharges, na.rm = TRUE), col = "red", main = "Density of MonthlyCharges") | |||||
| # Boxplot of Monthly Charges by Churn status | |||||
| boxplot(telco.df$MonthlyCharges ~ telco.df$Churn, | |||||
| main = "Monthly Charges by Churn Status", | |||||
| xlab = "Churn (Yes/No)", | |||||
| ylab = "Monthly Charges", | |||||
| col = c("red", "blue")) | |||||
| # Scatter plot of tenure vs Monthly Charges | |||||
| plot(telco.df$tenure, telco.df$MonthlyCharges, | |||||
| xlab = "Tenure (Months)", | |||||
| ylab = "Monthly Charges ($)", | |||||
| main = "Tenure vs. Monthly Charges", | |||||
| col = "blue", pch = 16) | |||||
| # Scatter plot of tenure vs churn with jitter | |||||
| ggplot(telco.df, aes(x = Churn, y = tenure, color = Churn)) + | |||||
| geom_jitter(width = 0.2, alpha = 0.6) + | |||||
| labs(title = "Tenure by Churn Status", | |||||
| x = "Churn (Yes/No)", | |||||
| y = "Tenure (Months)") + | |||||
| theme_minimal() | |||||
| # Convert Tenure to years | |||||
| telco.df$TenureYears <- telco.df$tenure / 12 | |||||
| # Ensure "DSL" is properly recognized in InternetService | |||||
| dsl_data <- subset(telco.df, InternetService == "DSL", select = c(TenureYears, MonthlyCharges)) | |||||
| # Scatter plot for DSL customers | |||||
| ggplot(dsl_data, aes(x = TenureYears, y = MonthlyCharges)) + | |||||
| geom_point(color = "blue", alpha = 0.6) + | |||||
| labs(title = "Monthly Charges vs. Tenure (DSL Customers)", | |||||
| x = "Tenure (Years)", | |||||
| y = "Monthly Charges ($)") + | |||||
| theme_minimal() | |||||
+ 38
- 0
Project/tempt-code.R
View File
| @ -0,0 +1,38 @@ | |||||
| # Telco Customer Churn Analysis Script | |||||
| # Load required libraries | |||||
| library(ggplot2) | |||||
| library(dplyr) | |||||
| library(rpart) | |||||
| library(e1071) | |||||
| library(caret) | |||||
| library(pROC) | |||||
| # Load dataset | |||||
| telco <- read.csv("Telco-Customer-Churn.csv", stringsAsFactors = TRUE) | |||||
| telco$TotalCharges <- as.numeric(as.character(telco$TotalCharges)) | |||||
| telco <- telco[!is.na(telco$TotalCharges), ] | |||||
| telco$Churn <- factor(telco$Churn, levels = c("No", "Yes")) | |||||
| # Split data | |||||
| set.seed(42) | |||||
| trainIndex <- createDataPartition(telco$Churn, p = 0.7, list = FALSE) | |||||
| train <- telco[trainIndex, ] | |||||
| test <- telco[-trainIndex, ] | |||||
| # Decision Tree model | |||||
| dt_model <- rpart(Churn ~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, | |||||
| data = train, method = "class") | |||||
| dt_pred <- predict(dt_model, test, type = "class") | |||||
| dt_conf <- confusionMatrix(dt_pred, test$Churn) | |||||
| # Naive Bayes model | |||||
| nb_model <- naiveBayes(Churn ~ tenure + MonthlyCharges + TotalCharges + SeniorCitizen, | |||||
| data = train) | |||||
| nb_pred <- predict(nb_model, test) | |||||
| nb_conf <- confusionMatrix(nb_pred, test$Churn) | |||||
| # ROC | |||||
+ 7044
- 0
Telco-Customer-Churn.csv
File diff suppressed because it is too large
View File
BIN
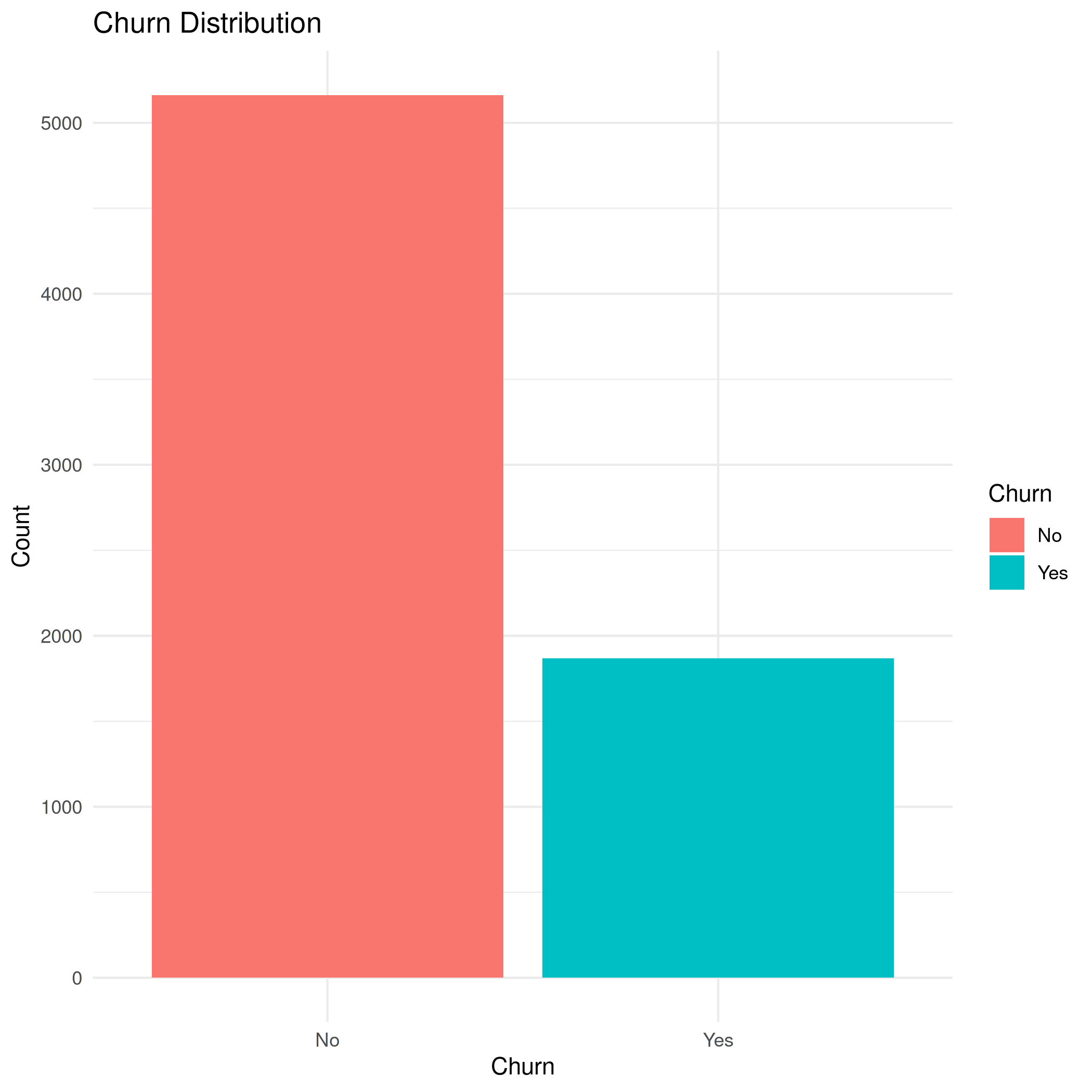
bar_churn.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 55 KiB |
BIN
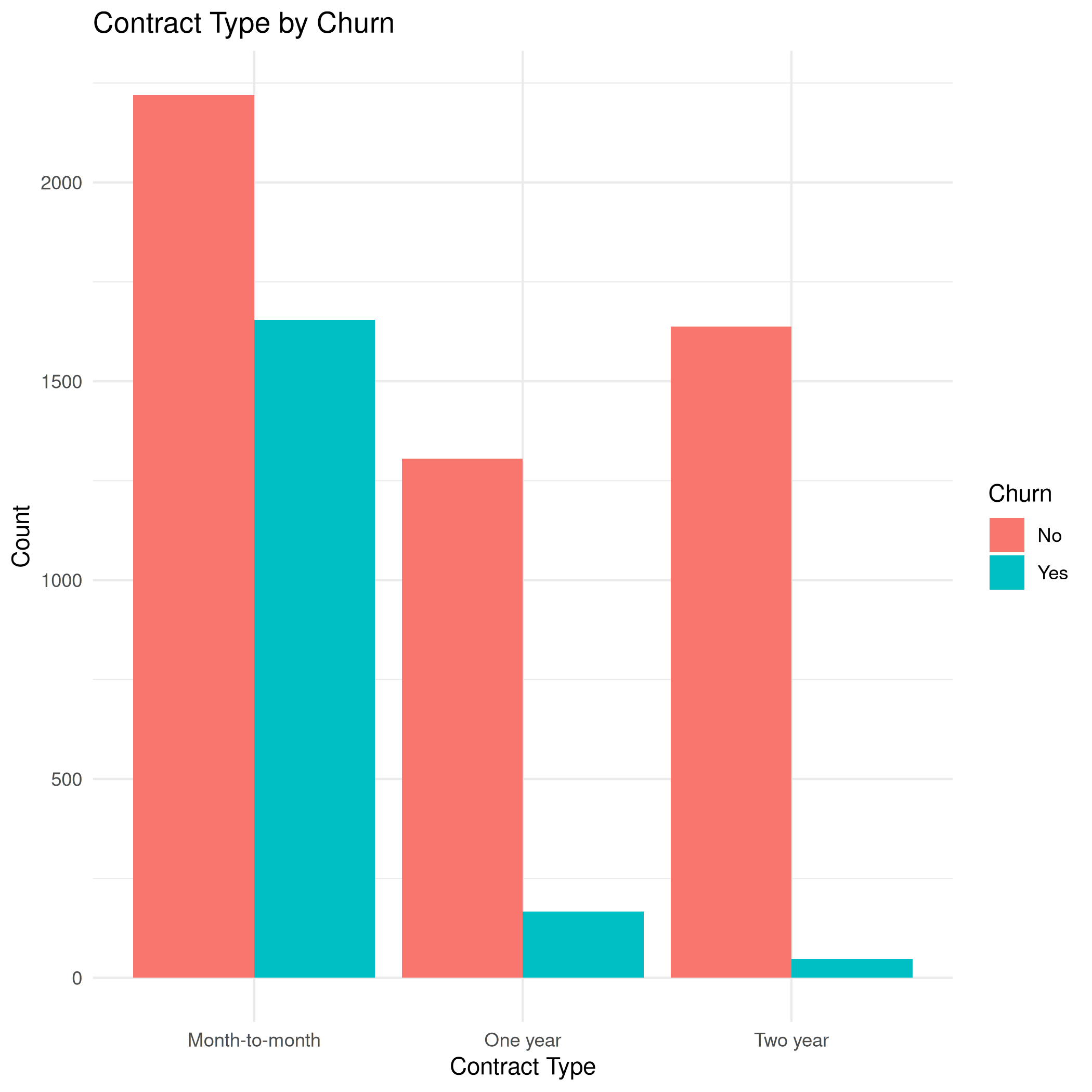
bar_contract_churn.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 69 KiB |
BIN
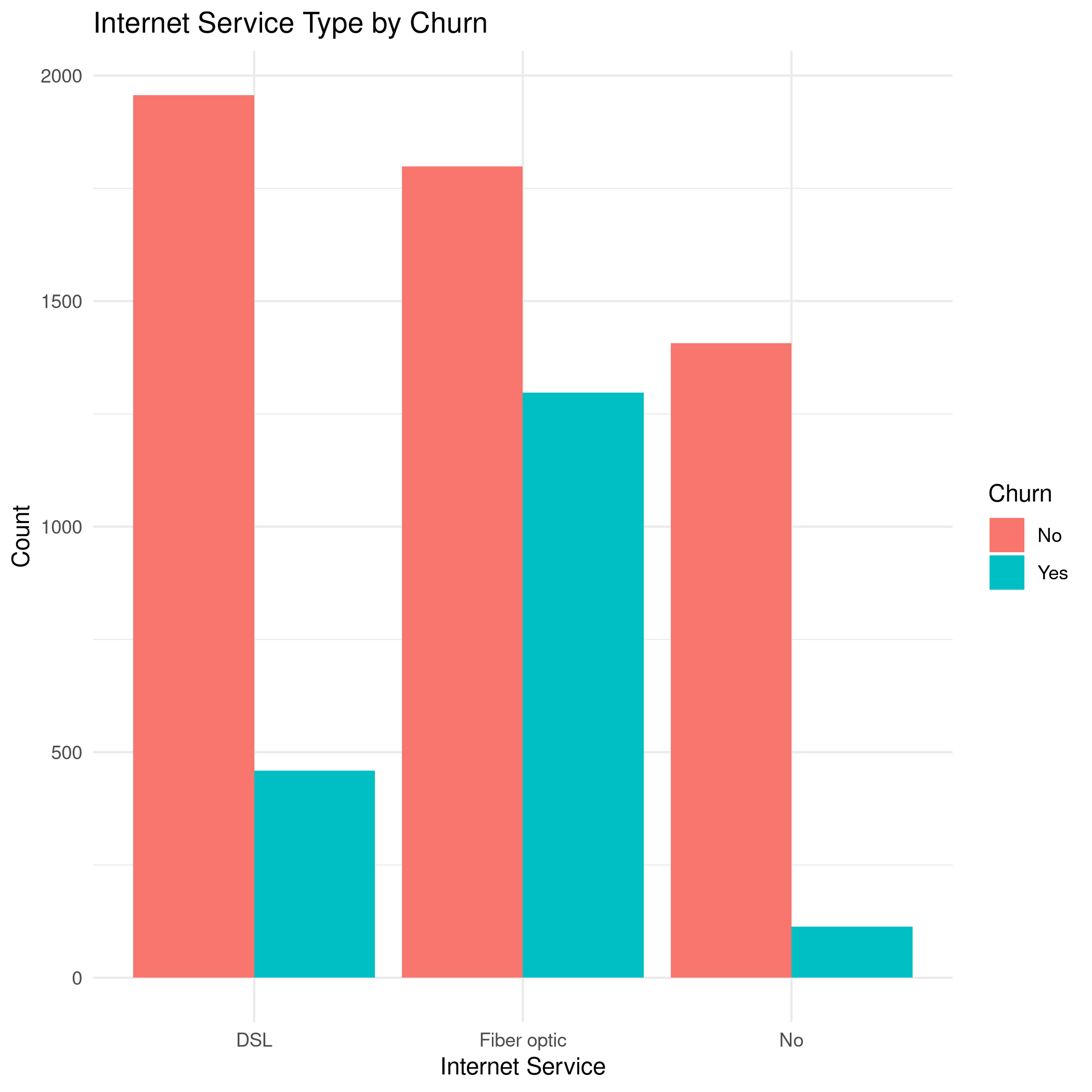
bar_internetservice_churn.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 62 KiB |
BIN
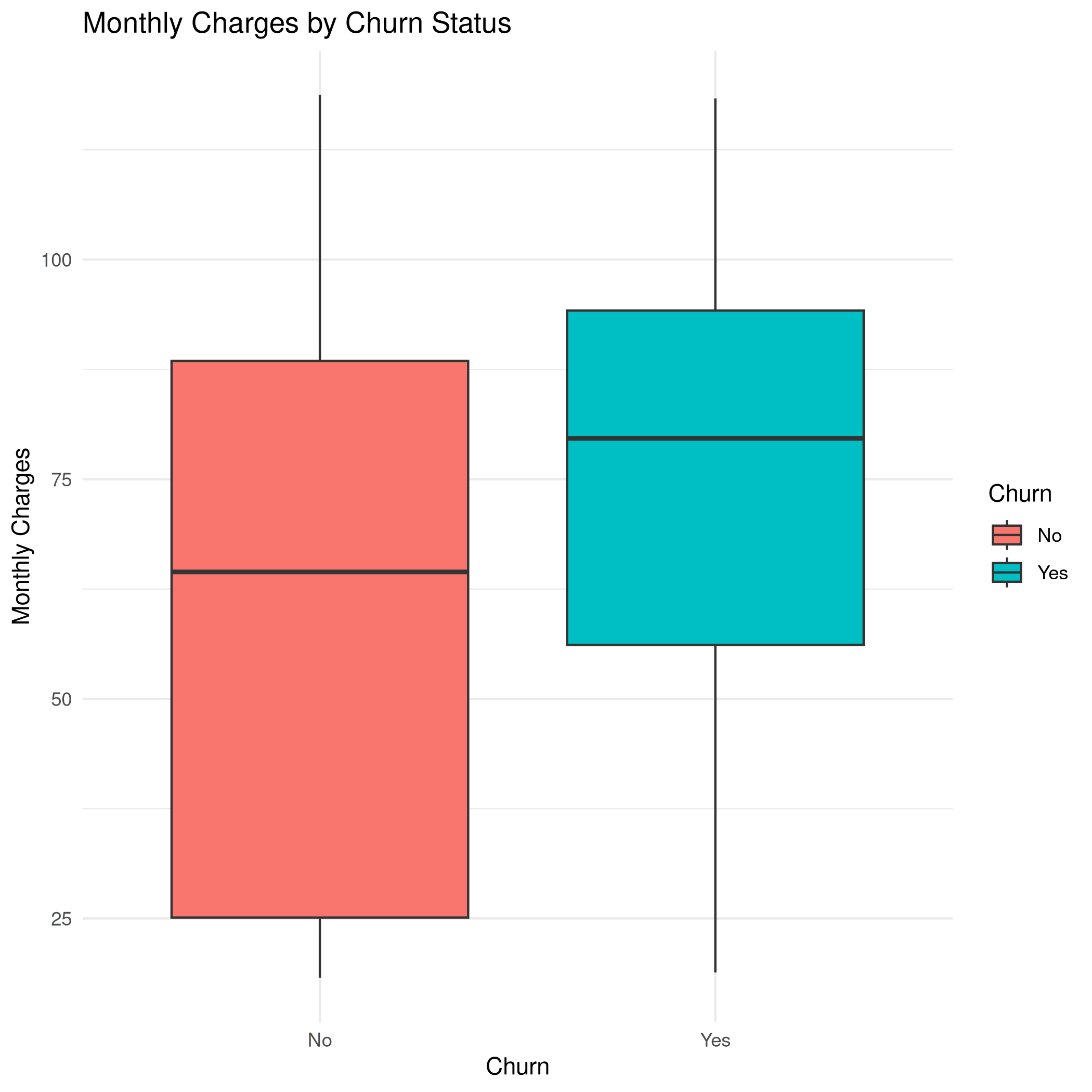
boxplot_monthlycharges_churn.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 62 KiB |
BIN
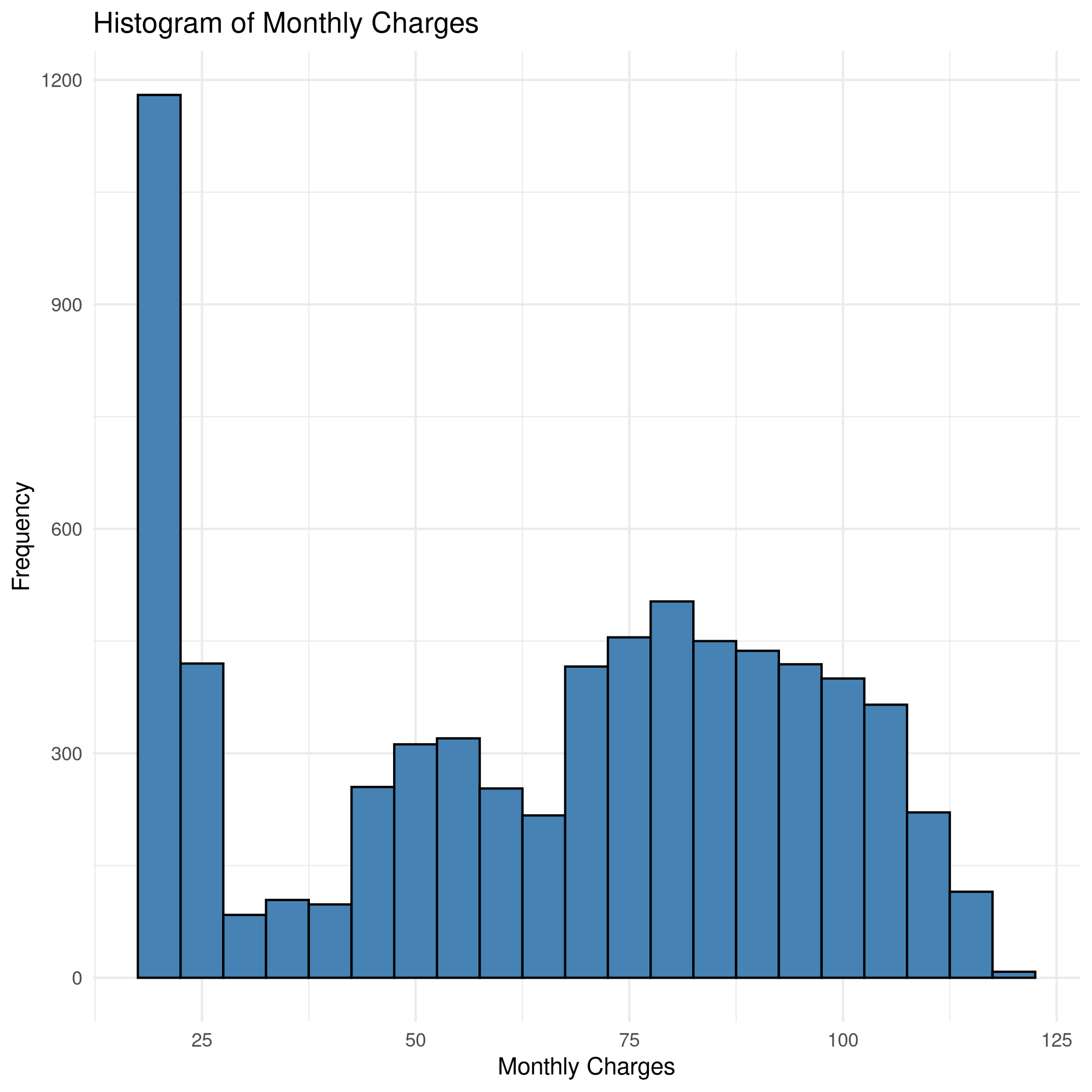
hist_monthlycharges.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 69 KiB |
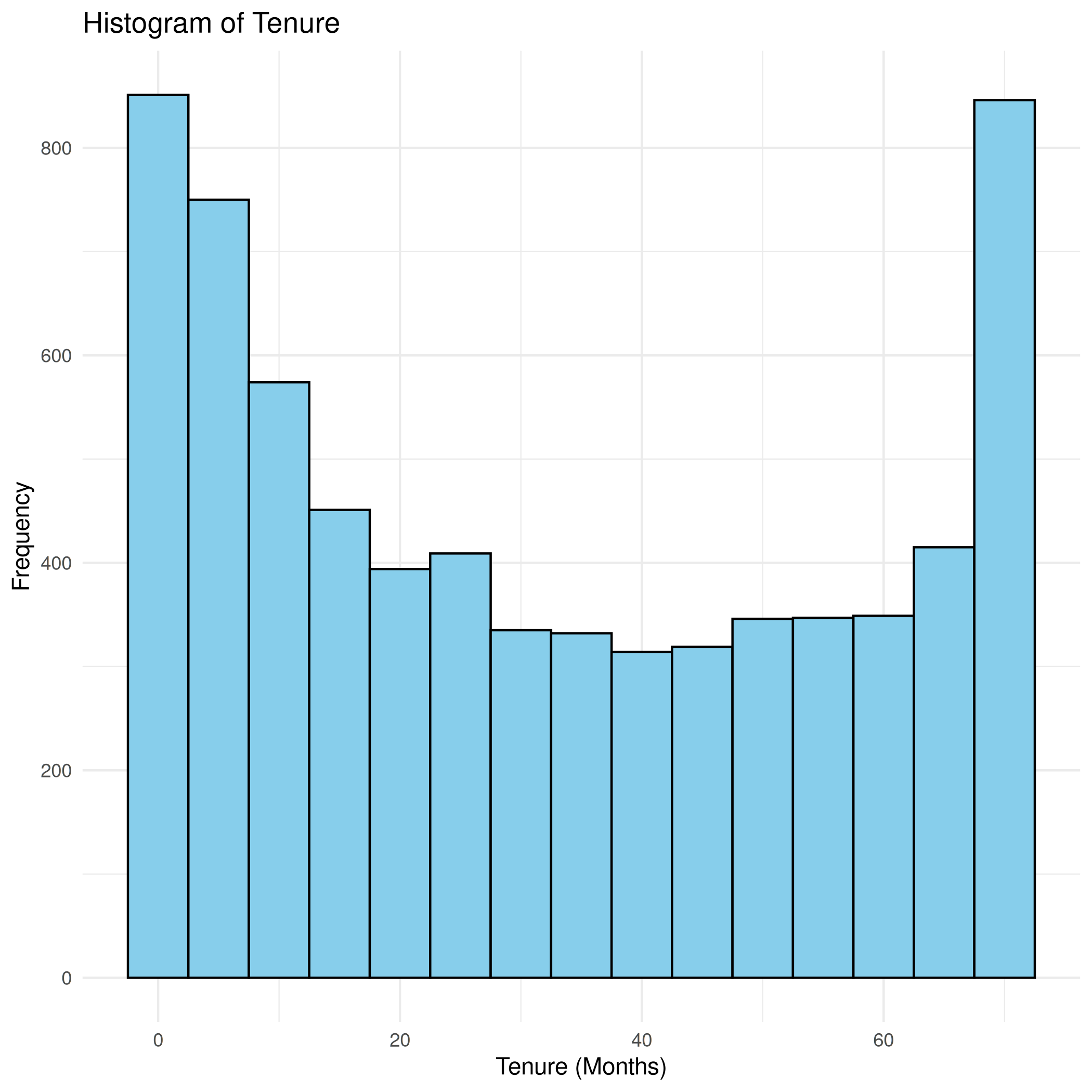
BIN
hist_tenure.png
View File
{kind=link}
| Before | After |
|---|---|
|
|
| Width: 2100 | Height: 2100 | Size: 59 KiB |